Variational Auto-Encoder#
The objective of a generative model is to represent (modeling) the distribution \(p(x)\) of observed data \(x\). Once the distribution \(p(x)\) is obtained, new (pseudo) data can be generated (sampling) from that distribution.
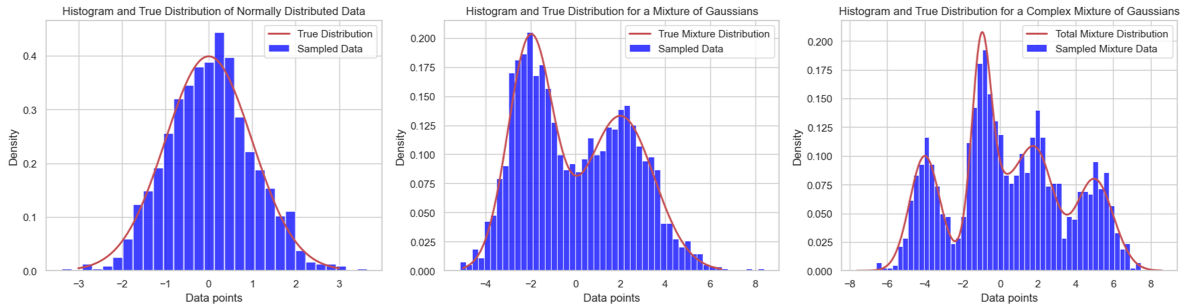
In the realm of data modeling, starting with the simplest cases often sets the groundwork for understanding more complex scenarios. Consider the first figure, where data is modeled using a single Gaussian distribution—a case of profound simplicity. However, the reality of the data we encounter in this world is more complex.
As we move towards more intricate examples, like those depicted in the middle and right figures, it becomes evident that the data observed in real-world applications often possesses complex distributions. These complexities challenge us to develop models that can flexibly adapt to data’s actual shapes and behaviors. This is where Variational Autoencoders (VAEs) come into play.
VAEs are a class of latent variable models designed to address these challenges by providing a robust framework for modeling data distributions that are difficult to capture with traditional methods. By leveraging the principles of probabilistic inference and deep learning, VAEs enable us to approximate these complex distributions with remarkable precision and flexibility.
Overview of VAE#
One of the representative latent variable models is the Variational Auto-Encoder (VAE). The idea in VAE is that the model learns to generate the data by encoding the observed data into a latent space (as a latent variable) and restoring the original observed data. The encoding and restoring (decoding) processes are conducted with neural networks. A main difference between VAE and other latent variable models is that, in VAE, the latent variable \(z\) is generated from a fixed normal distribution.
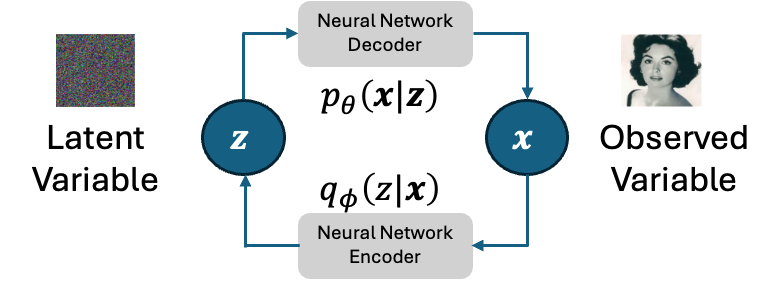
Recall that the objective of the generative model is to obtain the distribution \(p(x)\) of the observed data \(x\). Therefore, the neural network decoder should be modeled as \(p(x|z) \). However, the neural network output is a vector, so it cannot be directly used as the distribution. To this end, we consider using a normal distribution whose mean vector is the output of the neural network decoder. This can be represented as the following equations, where \(\theta\) is the parameters of the neural network decoder. We set the covariance matrix to a unit matrix \(\text{I}\) for simplicity.
For the encoder, since the latent variable in VAE is assumed to be generated from a fixed normal distribution, the transformation process from the observed variable to the latent variable can be modeled as follows, where \(\phi\) is the parameters of the neural network encoder.
Parameter Estimation for VAE#
Similar to the EM algorithm, here we consider using ELBO to maximize the log-likelihood function of the model. With observed data (samples) \(\mathcal{D}=\{x^{(1)}, x^{(2)}, ..., x^{(N)}\}\) ELBO of VAE can be calculated as follows.
Let’s consider ELBO of one sample \(\text{ELBO}(x;\theta,\phi)\).
The first part, \(\mathbb{E}_{q_\phi(z|x)}\left[\log p_\theta(x|z)\right]\) , is an expectation value of \(\log p_\theta(x|z)\), thus, can be approximately calculated with Monte Carlo method as follows, where \(x_d, \hat{x}_d\) are \(d\)-th component of \(D\)-dimension vector \(x, \hat{x}\), respectively.
The second part, \(D_{\text{KL}}(q_\phi(z|x)\|p(z))\), is the KL divergence between two normal distributions. Thus, it can be obtained as follows, where \(\mu_h , \sigma_h\) are \(h\)-th component of \(H\)-dimension vectors \(\mu, \sigma\) (output of the neural network encoder).
Hence, the ELBO can be obtained as follows.
We need to maximize this ELBO to estimate the parameters for the VAE model. However, with neural networks, it is more natural to do minimization on a loss function. Thus, we can define a loss function for neural network encoder and decoder training.
A Practical Example: Image Generation with VAE#
Step 1: Import Necessary Libraries#
import torch
from torch import nn, optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
import numpy as np
Step 2: Define the Encoder and Decoder#
Both the encoder and decoder will be modeled as simple Multi-Layer Perceptrons (MLPs).
class Encoder(nn.Module):
def __init__(self, input_dim, hidden_dim, z_dim):
super(Encoder, self).__init__()
self.linear = nn.Linear(input_dim, hidden_dim)
self.mu = nn.Linear(hidden_dim, z_dim)
self.log_var = nn.Linear(hidden_dim, z_dim)
def forward(self, x):
x = torch.relu(self.linear(x))
mu = self.mu(x)
log_var = self.log_var(x)
return mu, log_var
class Decoder(nn.Module):
def __init__(self, z_dim, hidden_dim, output_dim):
super(Decoder, self).__init__()
self.linear = nn.Linear(z_dim, hidden_dim)
self.out = nn.Linear(hidden_dim, output_dim)
def forward(self, z):
z = torch.relu(self.linear(z))
return torch.sigmoid(self.out(z))
Step 3: Define the VAE#
class VAE(nn.Module):
def __init__(self, input_dim, hidden_dim, z_dim):
super(VAE, self).__init__()
self.encoder = Encoder(input_dim, hidden_dim, z_dim)
self.decoder = Decoder(z_dim, hidden_dim, input_dim)
# Reparameterization Trick
def reparameterize(self, mu, log_var):
std = torch.exp(0.5 * log_var)
eps = torch.randn_like(std)
return mu + eps * std
def forward(self, x):
mu, log_var = self.encoder(x.view(-1, 28*28))
z = self.reparameterize(mu, log_var)
return self.decoder(z), mu, log_var
def loss_function(self, recon_x, x, mu, log_var):
BCE = nn.functional.binary_cross_entropy(recon_x, x.view(-1, 28*28), reduction='sum')
KLD = -0.5 * torch.sum(1 + log_var - mu.pow(2) - log_var.exp())
return BCE + KLD
Training#
from tqdm import tqdm
# Data loading
transform = transforms.Compose([
transforms.ToTensor()
])
train_dataset = datasets.FashionMNIST('./data', train=True, download=True, transform=transform)
train_loader = DataLoader(train_dataset, batch_size=128, shuffle=True)
# Model, Optimizer, and Device Setup
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
input_dim = 784 # 28 * 28 image
hidden_dim = 256
latent_dim = 128
model = VAE(input_dim, hidden_dim, latent_dim).to(device)
optimizer = optim.Adam(model.parameters(), lr=1e-3)
# Training Loop
def train(epoch):
model.train()
train_loss = 0
for batch_idx, (data, _) in enumerate(train_loader):
data = data.to(device)
optimizer.zero_grad()
recon_batch, mu, log_var = model(data)
loss = model.loss_function(recon_batch, data, mu, log_var)
loss.backward()
train_loss += loss.item()
optimizer.step()
# if batch_idx % 100 == 0:
# print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
# epoch, batch_idx * len(data), len(train_loader.dataset),
# 100. * batch_idx / len(train_loader), loss.item() / len(data)))
#print('====> Epoch: {} Average loss: {:.4f}'.format(
# epoch, train_loss / len(train_loader.dataset)))
return train_loss / len(train_loader.dataset)
# Run the training
loss_history = []
num_epochs = 30
for epoch in tqdm(range(1, num_epochs + 1)):
loss = train(epoch)
loss_history.append(loss)
Show code cell output
0%| | 0/30 [00:00<?, ?it/s]
3%|▎ | 1/30 [00:07<03:40, 7.61s/it]
7%|▋ | 2/30 [00:15<03:31, 7.54s/it]
10%|█ | 3/30 [00:22<03:23, 7.53s/it]
10%|█ | 3/30 [00:29<04:29, 9.98s/it]
---------------------------------------------------------------------------
KeyboardInterrupt Traceback (most recent call last)
Cell In[5], line 46
44 num_epochs = 30
45 for epoch in tqdm(range(1, num_epochs + 1)):
---> 46 loss = train(epoch)
47 loss_history.append(loss)
Cell In[5], line 25, in train(epoch)
23 model.train()
24 train_loss = 0
---> 25 for batch_idx, (data, _) in enumerate(train_loader):
26 data = data.to(device)
27 optimizer.zero_grad()
File ~/.cache/pypoetry/virtualenvs/loem-notes-kagQPLM5-py3.11/lib/python3.11/site-packages/torch/utils/data/dataloader.py:631, in _BaseDataLoaderIter.__next__(self)
628 if self._sampler_iter is None:
629 # TODO(https://github.com/pytorch/pytorch/issues/76750)
630 self._reset() # type: ignore[call-arg]
--> 631 data = self._next_data()
632 self._num_yielded += 1
633 if self._dataset_kind == _DatasetKind.Iterable and \
634 self._IterableDataset_len_called is not None and \
635 self._num_yielded > self._IterableDataset_len_called:
File ~/.cache/pypoetry/virtualenvs/loem-notes-kagQPLM5-py3.11/lib/python3.11/site-packages/torch/utils/data/dataloader.py:675, in _SingleProcessDataLoaderIter._next_data(self)
673 def _next_data(self):
674 index = self._next_index() # may raise StopIteration
--> 675 data = self._dataset_fetcher.fetch(index) # may raise StopIteration
676 if self._pin_memory:
677 data = _utils.pin_memory.pin_memory(data, self._pin_memory_device)
File ~/.cache/pypoetry/virtualenvs/loem-notes-kagQPLM5-py3.11/lib/python3.11/site-packages/torch/utils/data/_utils/fetch.py:51, in _MapDatasetFetcher.fetch(self, possibly_batched_index)
49 data = self.dataset.__getitems__(possibly_batched_index)
50 else:
---> 51 data = [self.dataset[idx] for idx in possibly_batched_index]
52 else:
53 data = self.dataset[possibly_batched_index]
File ~/.cache/pypoetry/virtualenvs/loem-notes-kagQPLM5-py3.11/lib/python3.11/site-packages/torch/utils/data/_utils/fetch.py:51, in <listcomp>(.0)
49 data = self.dataset.__getitems__(possibly_batched_index)
50 else:
---> 51 data = [self.dataset[idx] for idx in possibly_batched_index]
52 else:
53 data = self.dataset[possibly_batched_index]
File ~/.cache/pypoetry/virtualenvs/loem-notes-kagQPLM5-py3.11/lib/python3.11/site-packages/torchvision/datasets/mnist.py:146, in MNIST.__getitem__(self, index)
143 img = Image.fromarray(img.numpy(), mode="L")
145 if self.transform is not None:
--> 146 img = self.transform(img)
148 if self.target_transform is not None:
149 target = self.target_transform(target)
File ~/.cache/pypoetry/virtualenvs/loem-notes-kagQPLM5-py3.11/lib/python3.11/site-packages/torchvision/transforms/transforms.py:95, in Compose.__call__(self, img)
93 def __call__(self, img):
94 for t in self.transforms:
---> 95 img = t(img)
96 return img
File ~/.cache/pypoetry/virtualenvs/loem-notes-kagQPLM5-py3.11/lib/python3.11/site-packages/torchvision/transforms/transforms.py:137, in ToTensor.__call__(self, pic)
129 def __call__(self, pic):
130 """
131 Args:
132 pic (PIL Image or numpy.ndarray): Image to be converted to tensor.
(...)
135 Tensor: Converted image.
136 """
--> 137 return F.to_tensor(pic)
File ~/.cache/pypoetry/virtualenvs/loem-notes-kagQPLM5-py3.11/lib/python3.11/site-packages/torchvision/transforms/functional.py:174, in to_tensor(pic)
172 img = img.view(pic.size[1], pic.size[0], F_pil.get_image_num_channels(pic))
173 # put it from HWC to CHW format
--> 174 img = img.permute((2, 0, 1)).contiguous()
175 if isinstance(img, torch.ByteTensor):
176 return img.to(dtype=default_float_dtype).div(255)
KeyboardInterrupt:
Show code cell source
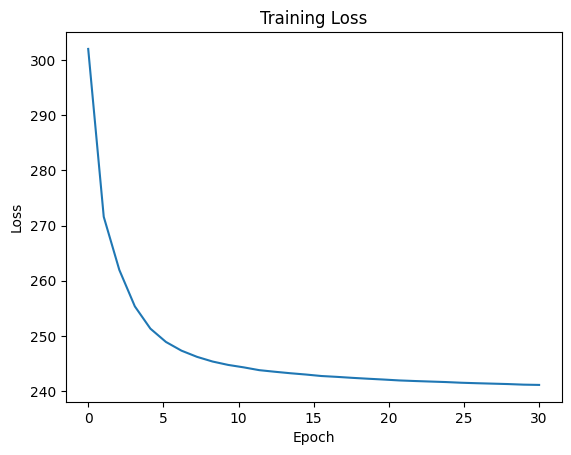
plt.plot(np.linspace(0, num_epochs, num_epochs), loss_history, "-")
plt.title("Training Loss")
plt.xlabel("Epoch")
plt.ylabel("Loss")
plt.show()
Generate New Image#
def generate_images(model, num_images=10):
model.eval()
with torch.no_grad():
# Sample z from the prior (standard normal distribution)
z = torch.randn(num_images, latent_dim).to(device)
generated_images = model.decoder(z)
generated_images = generated_images.view(num_images, 28, 28).cpu().numpy()
fig, ax = plt.subplots(figsize=(15, 15), nrows=1, ncols=num_images, sharey=True, sharex=True)
for i in range(num_images):
ax[i].imshow(generated_images[i], cmap='gray')
ax[i].axis('off')
plt.subplots_adjust(wspace=0, hspace=0)
plt.show()
generate_images(model)

Hierarchical VAE#
VAE is an effective generative model that is applied to many generative tasks. While there is only one latent variable in VAE, increasing the number of latent variables to form a hierarchy version of VAE can improve the representation capability of the model on more complex observed data.
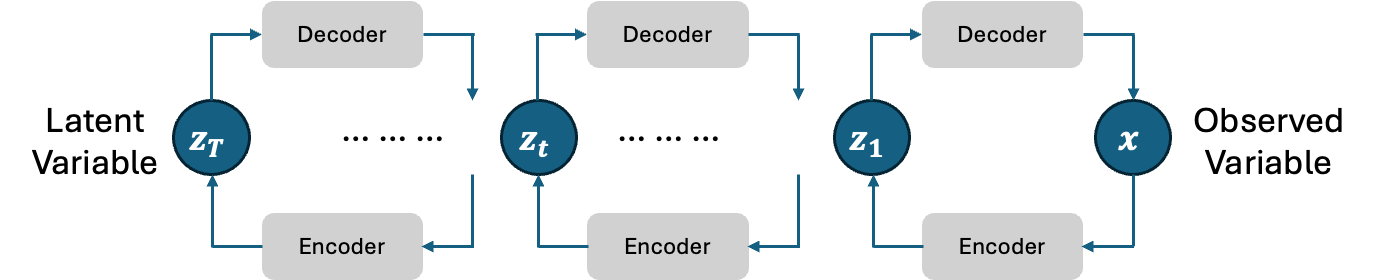
However, as you may have noticed, as the number of latent variables increases, the numbers of encoder and decoder also increase. This leads to many parameters to be trained, which is generally computationally high-cost.